In search of lightning feedback loop in a large codebase
As software developers, when we touch a codebase, we want the edit-compile cycle, to be as short as possible. Studies show that feedback loop less than 1s, or 100ms will prevent devleopers getting distracted.
This seems to be possible in a small project, but as project grows to 10k files, or even more, 100k files in a large company like Google, Facebook, this seems to be extremely challenging.
In this article, we are talking about how BuckleScript - it supports both OCaml and ReasonML syntax - is trying to solve this issue.
The edit-build cycle in BuckleScript consists of two components: the compiler which does type checking and code generation and the scheduler which figures out what to rebuild and how to do it concurrently.
The importance of compiler's cold performance
In order to reduce the edit-build latency, some languages adopt an approach of in memory compiler + watch mode. We think this is not a scalable or reliable approach.
A compiler is a complex piece of software, the chance that a compiler has memory leak is not low. It is not observed in real world since compiler is used mostly in a short-lived setting, it starts up fast and dies off quickly.
However, this is decimated when compiler is put in server mode. When we have 10k or 100k files held in memory, it is very easy to observe OOM (out of memory issues).
We figured that to deliver a scalable and reliable system, it is better to decouple the compiler's complexity from the scheduler. When the compiler cold starts and dies off quickly, the operating system process mechanism serves as an obviously correct garbage collector, which increases the reliability of the whole system.
To reduce such latency in a single compiler's workload, we spent lots of time tweaking the performance of the compiler itself, for example, rewriting the hot path in C code, most BuckleScript compiler source code is written in an imperative C-style to avoid allocation.
To have a general idea of how fast BuckleScript's compiler runs:
test>cat fib.ml
let rec fib = function
| 0 | 1 -> 1
| n -> fib (n - 1) + fib (n - 2)
test>time /usr/local/lib/node_modules/bs-platform/lib/bsc.exe -bs-cmi -bs-cmj -c fib.ml
real 0m0.008s
user 0m0.004s
sys 0m0.003s
Having a compiler run fast with a cold start lays the groundwork so that it won't be the bottleneck in the whole process. This is because when the architecture decouple the compiler from the scheduler, the compiler will be invoked by the scheduler hunderds of thousands of times in a build cycle, the latency of the compiler in a single compilation unit will add up.
The art of being incremental
Having a compiler running fast in cold mode does not solve the scalability issue alone. Take a code base which contains 100K source files for example, 100ms per file would result in 10,000s latency which is not acceptable. To solve such issue, we need reduce the workload as much as possible during each edit-build cycle.
In a statically typed language, suppose we have two compilation units A , B, and B depends on A. Whenever A changes, B gets recompiled, to make it worse, the recompilation propogates, all dependencies of B get recompiled, which will result in a snowball effect. In this model, whenever we touch the non-leaf compilation unit, the latency would be large.
The key observation here for BuckleScript is that B does not really
depend on the last modified time of A, it depends on the intermediate output of A (e.g, .cmj and .cmi file) which may not change even if we modify A. What we work on here is to reduce the probability of changing A's intermediate output due to changing A. With the integration of a scheduler, it can help stop the propagation as early as possible.
In BuckleScript, each compilation unit is composed of two files, the implementation file and interface file which are compiled to intermediate output .cmj and .cmi separately.
The interface builds are completely separate from implemetation, it does not depend on .cmj (implementation intermediate output) at all.
Suppose the interface is not changed, whenever we touch the implementation file, BuckleScript designs the data structure of .cmj in a way that the content of .cmj is seldom changed. (Let's say its probability is 0.05 which is rare in cases when the arity of a function changed)
If neither .cmj nor .cmi gets changed, the scheduler would stop propagation.
Suppose the .cmj file is still changed (P = 0.05), A's dependency B would get recompiled. Note B.cmi only depends on A.cmi, so it will not get compiled, only B.cmj will get recompiled, its chances that B.cmj gets changed will be even lower. In practice, the probabiity of the length of propagation chain is more than two is less than
0.05 * 0.05 = 0.0025
This means when we are in an edit-build cycle, whenever A gets changed, it may have many direct dependencies, but the longest rebuild sequence will get settled in at most two compilation units. Suppose the scheduler schedule the tasks in parallel, the longest sequence is bound by two, which means the rebuild cycle is very close to compiling two compilation units.
In implementation, we also generalized the idea of stopping propogation of .cmi changes, so whenever we are adding some comments in the interface file, it will get settled quickly.
The worst case is that the root of an interface changed. In such case, it does not mean all its dependencies will get recompiled, it depends on how many dependencies' interface depend on the root's interface. The cool thing is that since interface's dependency chain is completely decoupled from implementation's dependency, actually it used to be a subset of implementation's dependency chain, so only a subset of its dependencies will get compiled. We will see a concrete an example later.
A fast scheduler
As we said, the time spent in an edit-build cycle is mostly composed of two parts: compiling invoking the compiler, scheduling.
We are reusing the very fast scheduler provided by Ninja
Where other build systems are high-level languages, Ninja aims to be an assembler.
BuckleScript outputs assembler style instructions consumed by
Ninja which does scheduling very fast and provides good parallelism. By integrating with Ninja's restat attribute, we are able to implement the idea of a specialized content based build system.
It is fast enough for 99% of use cases. For a project less than 1k files, the time spent in an edit-build cycle is dominated by the compiler, but as project grows to 10K files or even more, the time spent in compiler is stable and bounded due to our incremental design, however, the time will start be dominated by the scheduler.
For a nop build around 10k files, it takes around 700ms for Ninja to figure out nothing needs to be rebuilt.
The current Ninja model is simple, every time it is invoked, it will re-read build.ninja instructions, check stats of artifacts and do the scheduling.
Instead of making a long-lived compiler, we propose to have a long-lived scheduler. The complexity of a scheduler is significantly lower than a compiler. Having an in-memory scheduler will help reducing redundant work such as parsing build.ninja instructions which is around of size 2M for 10k files. With the integration of watch mode, it does not need stat all artifacts each time, this should help increase the scalability of scheduler to 100K files or even more.
Tests on a synthetic benchmark
Our synthetic bench is borrowed from OMake and public available here.
The benchmark has these characteristics: The task is to build n^2 libraries with n^2 modules each (for a given small number n), and the dependencies between the modules are created in a way so that we can stress both the dependency analyzer of the build utility and the ability to run commands in parallel.
We modified the benchmark to add interface file for each implementation file.
The benchmark is running on MacBook Pro 18 with CPU 2.6 GHz Intel Core i7, Memory 32 GB 2400 MHz DDR4
The test is running against n = 3,5,7,9, where the source code size would be 2*3^4=162, 2*5^4=1250, 2*7^4=4802, 2*9**4=13122.
Below is what we get for a cold build from scratch:
| Source size | Clean build (ms) |
|---|---|
| 0162 | 684 |
| 1250 | 5,100 |
| 4802 | 24,112 |
| 13122 | 125,248 |
| Source size | Nop build (ms) | Touching root module (m_1_1_1_1.ml) | Touching (m_1_1_1.mli) |
|---|---|---|---|
| 0162 | 16 | 59 | 54 |
| 1250 | 79 | 120 | 133 |
| 4802 | 266 | 369 | 367 |
| 13122 | 728 | 963 | 962 |
We can see from the table as size grows, the time spent in edit-build cycle shifts from compilation to the scheduler, this is due to the fact that Ninja scheduler does not save the work for each test.
| Source size | Adding value to root module (m_1_1_1_1.ml) | Changing root interface |
|---|---|---|
| 0162 | 56 | 70 |
| 1250 | 131 | 155 |
| 4802 | 370 | 428 |
| 13122 | 969 | 991 |
The verbose build log for adding values on source of size 13122 is as below:
test9>ninja -C lib/bs -v
ninja: Entering directory `lib/bs'
[1/2] /usr/local/lib/node_modules/bs-platform/lib/bsc.exe -w -30-40+6+7+27+32..39+44+45+101 -nostdlib -I '/Users/hongbozhang/git/bsb-bench/test9/node_modules/bs-platform/lib/ocaml' -color always -c -o src/dir_1_1/m_1_1_1_1.mlast -bs-syntax-only -bs-binary-ast /Users/hongbozhang/git/bsb-bench/test9/src/dir_1_1/m_1_1_1_1.ml
[2/2] /usr/local/lib/node_modules/bs-platform/lib/bsb_helper.exe -g 0 -MD src/dir_1_1/m_1_1_1_1.mlast
[1/5905] /usr/local/lib/node_modules/bs-platform/lib/bsc.exe -bs-package-name test -bs-package-output commonjs:lib/js/src/dir_1_1 -bs-assume-has-mli -bs-no-builtin-ppx-ml -bs-no-implicit-include -I src/dir_4_6 -I src/dir_4_1 -I src/dir_4_8 -I src/dir_6_5 -I src/dir_6_2 -I src/dir_8_3 -I src/dir_8_4 -I src/dir_2_3 -I src/dir_2_4 -I src/dir_6_3 -I src/dir_4_9 -I src/dir_6_4 -I src/dir_4_7 -I src/dir_2_5 -I src/dir_2_2 -I src/dir_8_5 -I src/dir_8_2 -I src/dir_9_9 -I src/dir_3_7 -I src/dir_1_3 -I src/dir_9_7 -I src/dir_3_9 -I src/dir_1_4 -I src/dir_7_6 -I src/dir_7_1 -I src/dir_5_5 -I src/dir_7_8 -I src/dir_5_2 -I src/dir_3_8 -I src/dir_9_6 -I src/dir_1_5 -I src/dir_9_1 -I src/dir_1_2 -I src/dir_3_6 -I src/dir_9_8 -I src/dir_3_1 -I src/dir_5_3 -I src/dir_5_4 -I src/dir_7_9 -I src/dir_7_7 -I src/dir_8_7 -I src/dir_2_9 -I src/dir_8_9 -I src/dir_2_7 -I src/dir_4_2 -I src/dir_6_8 -I src/dir_4_5 -I src/dir_6_1 -I src/dir_6_6 -I src/dir_2_1 -I src/dir_2_6 -I src/dir_8_8 -I src/dir_8_1 -I src/dir_2_8 -I src/dir_8_6 -I src/dir_6_7 -I src/dir_6_9 -I src/dir_4_4 -I src/dir_4_3 -I src/dir_7_2 -I src/dir_7_5 -I src/dir_5_8 -I src/dir_5_1 -I src/dir_5_6 -I src/dir_1_9 -I src/dir_3_4 -I src/dir_3_3 -I src/dir_9_4 -I src/dir_1_7 -I src/dir_9_3 -I src/dir_5_7 -I src/dir_7_4 -I src/dir_5_9 -I src/dir_7_3 -I src/dir_9_2 -I src/dir_1_1 -I src/dir_9_5 -I src/dir_1_6 -I src/dir_3_2 -I src/dir_1_8 -I src/dir_3_5 -w -30-40+6+7+27+32..39+44+45+101 -nostdlib -I '/Users/hongbozhang/git/bsb-bench/test9/node_modules/bs-platform/lib/ocaml' -color always -o src/dir_1_1/m_1_1_1_1.cmj -c src/dir_1_1/m_1_1_1_1.mlast
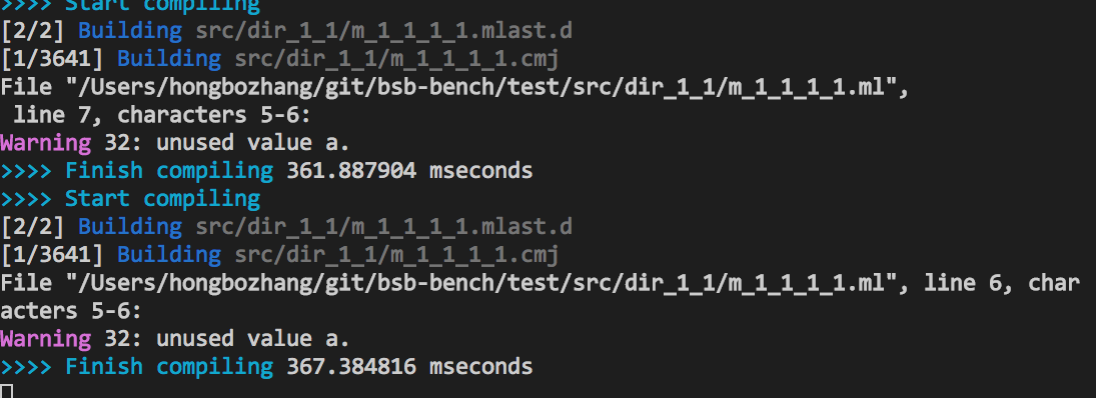
File "/Users/hongbozhang/git/bsb-bench/test9/src/dir_1_1/m_1_1_1_1.ml", line 4, characters 4-5:
Warning 32: unused value a.
Ignoring the preprocess stage, We can see there are 5906 jobs scheduled but only one job is processed. This is because adding a single value does not change m_1_1_1_1.cmj so that the change of propogation is stopped immediately.
The result is surprisingly good even if change the interface of root files, by looking at the verbose build log:
test9>ninja -C lib/bs -v
ninja: Entering directory `lib/bs'
[1/2] /usr/local/lib/node_modules/bs-platform/lib/bsc.exe -w -30-40+6+7+27+32..39+44+45+101 -nostdlib -I '/Users/hongbozhang/git/bsb-bench/test9/node_modules/bs-platform/lib/ocaml' -color always -c -o src/dir_1_1/m_1_1_1_1.mliast -bs-syntax-only -bs-binary-ast /Users/hongbozhang/git/bsb-bench/test9/src/dir_1_1/m_1_1_1_1.mli
[2/2] /usr/local/lib/node_modules/bs-platform/lib/bsb_helper.exe -g 0 -MD src/dir_1_1/m_1_1_1_1.mliast
[1/5906] /usr/local/lib/node_modules/bs-platform/lib/bsc.exe -bs-package-name test -bs-package-output commonjs:lib/js/src/dir_1_1 -bs-no-builtin-ppx-mli -bs-no-implicit-include -I src/dir_4_6 -I src/dir_4_1 -I src/dir_4_8 -I src/dir_6_5 -I src/dir_6_2 -I src/dir_8_3 -I src/dir_8_4 -I src/dir_2_3 -I src/dir_2_4 -I src/dir_6_3 -I src/dir_4_9 -I src/dir_6_4 -I src/dir_4_7 -I src/dir_2_5 -I src/dir_2_2 -I src/dir_8_5 -I src/dir_8_2 -I src/dir_9_9 -I src/dir_3_7 -I src/dir_1_3 -I src/dir_9_7 -I src/dir_3_9 -I src/dir_1_4 -I src/dir_7_6 -I src/dir_7_1 -I src/dir_5_5 -I src/dir_7_8 -I src/dir_5_2 -I src/dir_3_8 -I src/dir_9_6 -I src/dir_1_5 -I src/dir_9_1 -I src/dir_1_2 -I src/dir_3_6 -I src/dir_9_8 -I src/dir_3_1 -I src/dir_5_3 -I src/dir_5_4 -I src/dir_7_9 -I src/dir_7_7 -I src/dir_8_7 -I src/dir_2_9 -I src/dir_8_9 -I src/dir_2_7 -I src/dir_4_2 -I src/dir_6_8 -I src/dir_4_5 -I src/dir_6_1 -I src/dir_6_6 -I src/dir_2_1 -I src/dir_2_6 -I src/dir_8_8 -I src/dir_8_1 -I src/dir_2_8 -I src/dir_8_6 -I src/dir_6_7 -I src/dir_6_9 -I src/dir_4_4 -I src/dir_4_3 -I src/dir_7_2 -I src/dir_7_5 -I src/dir_5_8 -I src/dir_5_1 -I src/dir_5_6 -I src/dir_1_9 -I src/dir_3_4 -I src/dir_3_3 -I src/dir_9_4 -I src/dir_1_7 -I src/dir_9_3 -I src/dir_5_7 -I src/dir_7_4 -I src/dir_5_9 -I src/dir_7_3 -I src/dir_9_2 -I src/dir_1_1 -I src/dir_9_5 -I src/dir_1_6 -I src/dir_3_2 -I src/dir_1_8 -I src/dir_3_5 -w -30-40+6+7+27+32..39+44+45+101 -nostdlib -I '/Users/hongbozhang/git/bsb-bench/test9/node_modules/bs-platform/lib/ocaml' -color always -o src/dir_1_1/m_1_1_1_1.cmi -c src/dir_1_1/m_1_1_1_1.mliast
[2/5906] /usr/local/lib/node_modules/bs-platform/lib/bsc.exe -bs-package-name test -bs-package-output commonjs:lib/js/src/dir_1_1 -bs-assume-has-mli -bs-no-builtin-ppx-ml -bs-no-implicit-include -I ... -color always -o src/dir_1_1/m_1_1_1_1.cmj -c src/dir_1_1/m_1_1_1_1.mlast
[3/5906] /usr/local/lib/node_modules/bs-platform/lib/bsc.exe -bs-package-name test -bs-package-output commonjs:lib/js/src/dir_1_1 -bs-assume-has-mli -bs-no-builtin-ppx-ml -bs-no-implicit-include -I ... -w -30-40+6+7+27+32..39+44+45+101 -nostdlib -I '/Users/hongbozhang/git/bsb-bench/test9/node_modules/bs-platform/lib/ocaml' -color always -o src/dir_1_1/m_1_1_2_2.cmj -c src/dir_1_1/m_1_1_2_2.mlast
[4/5906] /usr/local/lib/node_modules/bs-platform/lib/bsc.exe -bs-package-name test -bs-package-output commonjs:lib/js/src/dir_1_1 -bs-assume-has-mli -bs-no-builtin-ppx-ml -bs-no-implicit-include -I ... -color always -o src/dir_1_1/m_1_1_2_1.cmj -c src/dir_1_1/m_1_1_2_1.mlast
[5/5906] /usr/local/lib/node_modules/bs-platform/lib/bsc.exe -bs-package-name test -bs-package-output commonjs:lib/js/src/dir_1_1 -bs-assume-has-mli -bs-no-builtin-ppx-ml -bs-no-implicit-include -I ... -color always -o src/dir_1_1/m_1_1_2_3.cmj -c src/dir_1_1/m_1_1_2_3.mlast
[6/5906] /usr/local/lib/node_modules/bs-platform/lib/bsc.exe -bs-package-name test -bs-package-output commonjs:lib/js/src/dir_1_1 -bs-assume-has-mli -bs-no-builtin-ppx-ml -bs-no-implicit-include -I ... -color always -o src/dir_1_1/m_1_1_2_9.cmj -c src/dir_1_1/m_1_1_2_9.mlast
[7/5906] /usr/local/lib/node_modules/bs-platform/lib/bsc.exe -bs-package-name test -bs-package-output commonjs:lib/js/src/dir_1_1 -bs-assume-has-mli -bs-no-builtin-ppx-ml -bs-no-implicit-include -I ... -color always -o src/dir_1_1/m_1_1_2_4.cmj -c src/dir_1_1/m_1_1_2_4.mlast
[8/5906] /usr/local/lib/node_modules/bs-platform/lib/bsc.exe -bs-package-name test -bs-package-output commonjs:lib/js/src/dir_1_1 -bs-assume-has-mli -bs-no-builtin-ppx-ml -bs-no-implicit-include -I ... -color always -o src/dir_1_1/m_1_1_2_5.cmj -c src/dir_1_1/m_1_1_2_5.mlast
[9/5906] /usr/local/lib/node_modules/bs-platform/lib/bsc.exe -bs-package-name test -bs-package-output commonjs:lib/js/src/dir_1_1 -bs-assume-has-mli -bs-no-builtin-ppx-ml -bs-no-implicit-include -I ... -color always -o src/dir_1_1/m_1_1_2_6.cmj -c src/dir_1_1/m_1_1_2_6.mlast
[10/5906] /usr/local/lib/node_modules/bs-platform/lib/bsc.exe -bs-package-name test -bs-package-output commonjs:lib/js/src/dir_1_1 -bs-assume-has-mli -bs-no-builtin-ppx-ml -bs-no-implicit-include -I ... -color always -o src/dir_1_1/m_1_1_2_7.cmj -c src/dir_1_1/m_1_1_2_7.mlast
[11/5906] /usr/local/lib/node_modules/bs-platform/lib/bsc.exe -bs-package-name test -bs-package-output commonjs:lib/js/src/dir_1_1 -bs-assume-has-mli -bs-no-builtin-ppx-ml -bs-no-implicit-include -I ... -color always -o src/dir_1_1/m_1_1_2_8.cmj -c src/dir_1_1/m_1_1_2_8.mlast
The log means that there are 5906 jobs to be scheduled but only 11 jobs processed. This is because there only 9 direct dependencies, the cmj/cmi changes' propogation stops in the first level of dependency, indirect dependencies are not propagated any more since the intermediate representation stays stable after that. There are 9 more jobs to do compared with changing implementation but the latency only increased by 30ms, which means the scheduler does a good job in parallelism.
The real world scenario may be a bit worse than our synthetic benchmark, since our syntethic benchmark only impose dependencies across implementation files, the dependencies across interface files are flat.
To conclude, currently BuckleScript scales very well to projects with around 10k files, and with some work in improving the scheduler, we believe it is not too difficult to scale it to 100K files or even more. To reach such enormous scalability in a reliable way, we propose to have a long-lived scheduler and fast cold compiler. The language interface design and the design of the data structure for the implementation will make the longest rebuild propogation chain bounded by two in most cases.